
Clear Web, Deep Web and Dark Web
An Introduction
All of you might have heard about the Internet and WWW, but today we’re about to examine the other side of the internet or how much do we know about the internet? Yes, as we always say there are two sides to a coin, there exists a dark side for the internet too.
Before going too deep into the WWW, we’ll see how to distinguish between the Clear, Deep and Dark webs. The illustration below can put some light on the things we are discussing here, ##
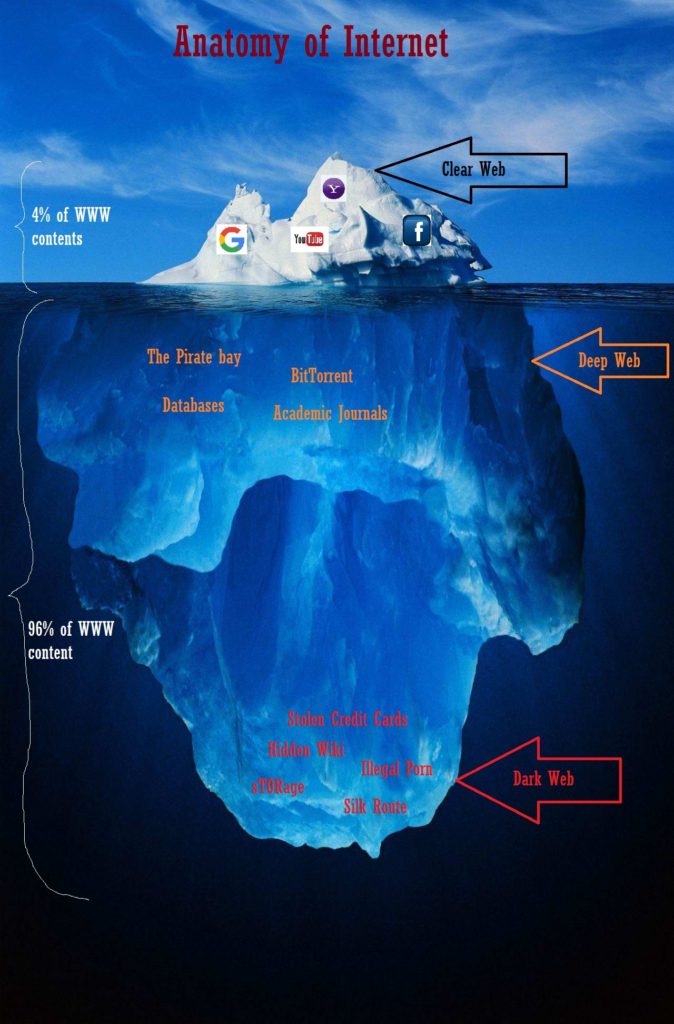
- Clear Web: This is the most common one. It’s the Internet we use on a daily basis either on mobiles or on Desktops/Laptops to check emails, to read news, to access Facebook, twitter, Instagram etc and for online shopping, booking tickets which we browse regularly.
- Deep Web: It is the part or a subset of the Internet that isn’t necessarily malicious, but is simply too large and/or obscure to be indexed due to the limitations of crawling and indexing software (like Google/Bing/Baidu). This means that you have to visit those places directly instead of being able to search for them. So there aren’t directions to get there, but they’re waiting if you have an address.
- Dark Web: The Dark Web (also called Darknet) is the ill-famed subset of the Deep Web that is not only not indexed, but also is used by those who are purposely trying to control access because they have a strong desire for privacy, or because what they’re doing is illegal. The Dark Web often sits on top of additional sub-networks, such as Tor, I2P, and Freenet, and is often associated with a criminal activity of various degrees, including buying and selling drugs, pornography, gambling, etc. Though the deep web makes up 95% of all the internet the dark web only consist of about .03%. But that small section has millions of monthly users. The dark web is usually what people actually mean when they refer to the deep web. Although both are technically correct it is important to keep it separated so there is a standardised phrase.
Deep Web & Dark Web
Computer scientist Mike Bergman is credited with coining these term in 2000. The Dark web is a small part of the Deep Web which is not indexed by search engines. Sometimes the term “deep web” is mistakenly used to refer specifically to the dark web. Most of the web’s information is buried far down on sites, and standard search engines do not find it. Traditional search engines like Google,Bing etc cannot see or retrieve content in the deep web. The portion of the web that is indexed by standard search engines is known as the surface web or clear net or clear web. As of 2001, the deep web was several orders of magnitude larger than the surface web.
- Dynamic content: dynamic pages which are returned in response to a submitted query or accessed only through a form, especially if open-domain input elements (such as text fields) are used; such fields are hard to navigate without domain knowledge.
- Unlinked content: pages which are not linked to by other pages, which may prevent web crawling programs from accessing the content. This content is referred to as pages without backlinks (also known as in links). Also, search engines do not always detect all backlinks from searched web pages.
- Private Web: sites that require registration and login (password-protected resources).
- Contextual Web: pages with content varying for different access contexts (e.g., ranges of client IP addresses or previous navigation sequence).
- Limited access content: sites that limit access to their pages in a technical way (e.g., using the Robots Exclusion Standard or CAPTCHAs, or no-store directive which prohibit search engines from browsing them and creating cached copies).
- Scripted content: pages that are only accessible through links produced by JavaScript as well as content dynamically downloaded from Web servers via Flash or Ajax solutions.
- Non-HTML/text content: textual content encoded in multimedia (image or video) files or specific file formats not handled by search engines.
- Software: certain content is intentionally hidden from the regular internet, accessible only with special software, such as Tor, I2P, or other darknet software. For example, Tor allows users to access websites using the .onion host suffix anonymously, hiding their IP address.
- Web archives: Web archival services such as the Wayback Machine enable users to see archived versions of web pages across time, including websites which have become inaccessible, and are not indexed by search engines such as Google.
How to access
Tor
.onion
Steps to accessing the Dark Web
Download and install TOR Browser Bundle from the TOR project site.
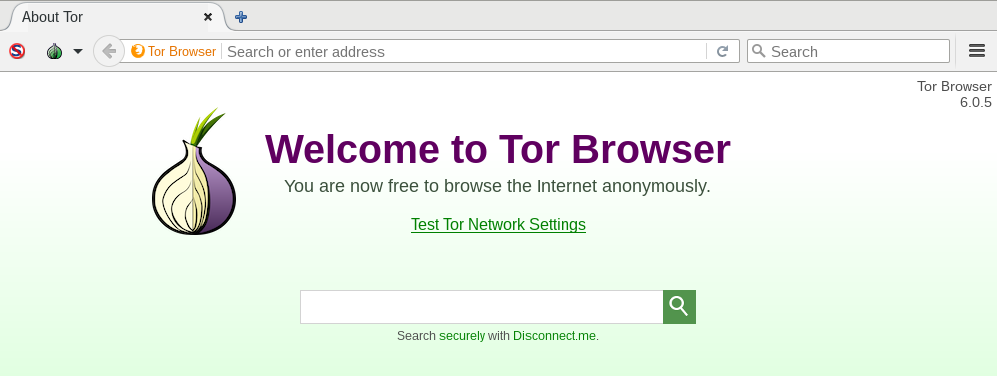
http://zqktlwi4fecvo6ri.onion/wiki/index.php/Main_Page

More onion URLs are found in the Hidden Wiki
## – This illustration is just for demonstration purpose
** – This content is as is fromWikipedia
Disclaimer:
This is a personal blog. All content provided on this blog is for informational purposes only. They are collated from different sources and some are my own.The owner of this blog makes no representations as to the accuracy or completeness of any information on this site or found by following any link on this site.
The owner of THIS BLOG will not be liable for any errors or omissions in this information nor for the availability of this information. The owner will not be liable for any losses, injuries, or damages from the display or use of this information
Data courtesy : Rational Wiki, Popular Science, Wired.com, TORProject, Hacked